How We Watch Our Own Infrastructure
There's a version of sovereignty about where the data lives, and another about the discipline of the operator. Here's how we track the second one.
When you store data with a cloud provider, you're trusting that they notice problems before you do. A patched server is one the operator went and patched. A predictable bill is one the operator built the discipline to predict. Most of what determines whether a provider is good or bad is invisible from the outside - it's how seriously they take their own internal operational discipline.
Over the last few weeks I've been building Storm Developments' internal operations dashboard. It's the console we use to track every server in our fleet: what each one is doing, what it costs, what's been hardened, what's overdue. Customer trust starts here, not on the marketing page.
Security
Every server we run is supposed to follow a versioned hardening playbook - the Ubuntu Baseline playbook for general VPSes, the Garage Hardening playbook for storage nodes, Caddy Baseline for reverse proxies, and so on. Each playbook has numbered steps. Each step gets applied to each server and signed off, and the sign-offs expire on a schedule so "we hardened that box a year ago" doesn't quietly drift into "we don't know the current state of that box anymore."
The dashboard tells us, in real time, which servers are overdue for what. Vulnerabilities discovered in third-party software are recorded as CVEs against the affected servers and tracked until they're patched or formally suppressed with written reasoning. There is no "we'll get to it" - either a CVE is resolved, or there's a record of who decided to leave it alone and why.
Most of the time, the queue is empty. That isn't an accident, it's the point.
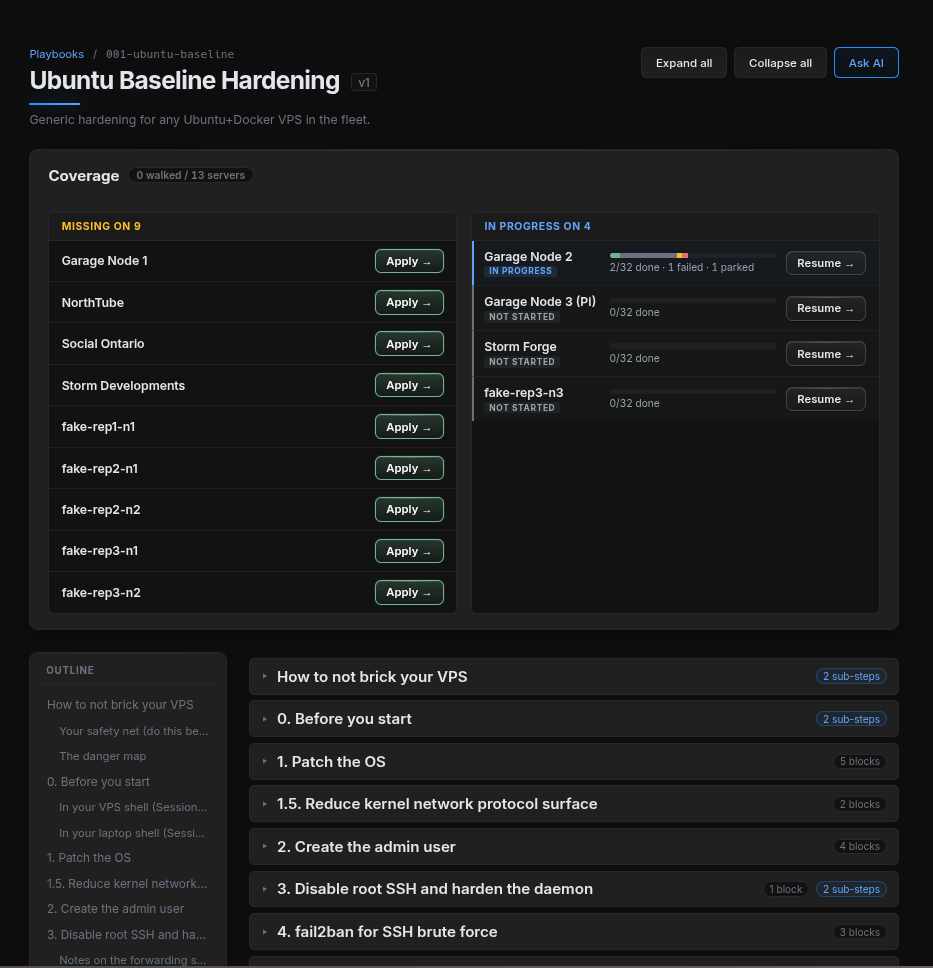
(All data inside images of this post is fake. Real production data is kept internal)
Finance
The same dashboard tracks every dollar the infrastructure costs - per server, per provider, per environment, per service. We know the monthly spend on every node, the breakdown by provider, and the breakdown by what each box is running (Garage storage, Mastodon, PeerTube, our internal forge).
For Storm Cellar specifically there's a dedicated Garage Economics view that decomposes storage costs into the parts most providers leave invisible. The Raw $/GB - what the underlying disk costs. The Effective $/GB - what a sellable GB really costs after replication overhead. The Replication Tax - the monthly cost of redundant copies that customers can't directly pay for. The Idle Capacity - the cost of empty space waiting to be filled.
The point of decomposing the cost this way isn't to charge customers more. It's the opposite. When we set a price like $9 USD per TB per month, that number has to defend itself against the actual cost of running the storage, with enough margin to operate sustainably and not so much that we're charging for empty space.
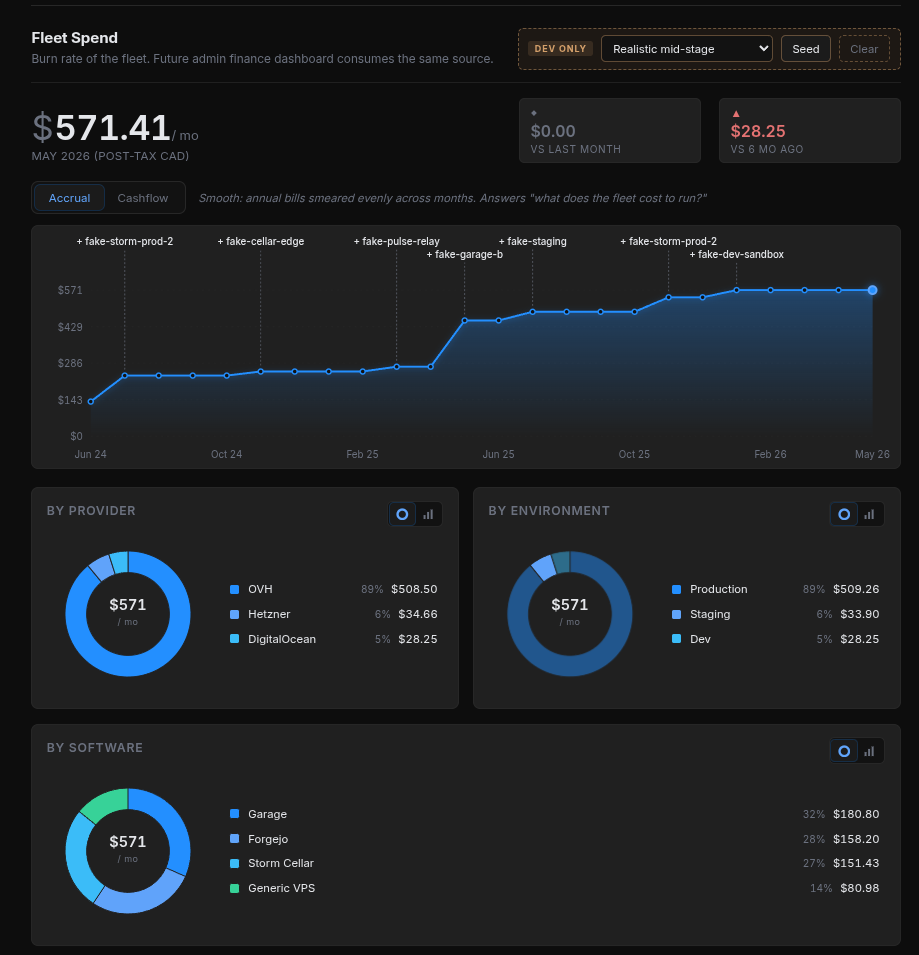
What Customers Actually Get
Customers don't see this dashboard. They shouldn't have to. What they should see is the result: a provider that patches its servers on a schedule, knows what's running on every box, and sets prices grounded in real math rather than aspirational margins. The dashboard is how we keep ourselves honest about delivering those things.
There's a version of sovereignty that's about where the data lives. There's another version that's about the discipline of the operator. Storm Developments tries to deliver both, and the second one is harder to see from the outside. This post is a partial view of how we make sure it's actually there.